1. Introduction to the Monte Carlo method#
Monte Carlo methods are those numerical approaches to any problem in which random numbers feature one way or another. Although the general idea is far from new, it came to fruition with the advent of computers in the 1940’s and became increasingly capable with our ever-increasing computing power. Nowadays, it is employed all across the natural sciences, computing, mathematics, engineering, finance, computer graphics, artificial intelligence, social sciences.

Fig. 1.1 The Monte Carlo Casino in Monaco.#
A little history
The Monte Carlo method in its modern form is often attributed to the work of the mathematician Stanislaw Ulam in the late forties at Los Alamos as part of the H-bomb development team. Calculations of the nuclear chain reactions were posing significant mathematical challenges and Ulam realized that the novel computer they had at the time could be employed more effectively by employing random numbers. Actually his idea was sparked not by his research but by his desire to figure out the chances of winning the card game of solitaire/patience: he had difficulty figuring out the math and philosophized that simulating the game many times on the (multi-million dollar) computer would give an accurate estimate. Because the project was classified at the time, Ulam together with his colleagues von Neumann and Metropolis had to think of a code name for the method, which they based on the famous Monte Carlo casino in Monaco.
Instead of jumping into the mathematics and probability theory underlying the technique or introducing the breadth of available Monte Carlo methods, we will start by looking at several very simple problems to get a feeling for what is ahead of us. This material is largely adapted from the introduction of [Kra06].
1.1. Direct sampling: pebble game 1.0#
The problem of sampling, i.e. obtaining random samples from a desired distribution, is in general very difficult. In fact, a significant part of this course is geared towards developing increasingly powerful methods to attack such problems. To grasp the idea we start by looking at a very simple game, which we can imagine children playing in a school yard. They draw an exact square and a circle inscribed it and from a distance they start throwing pebbles at it.
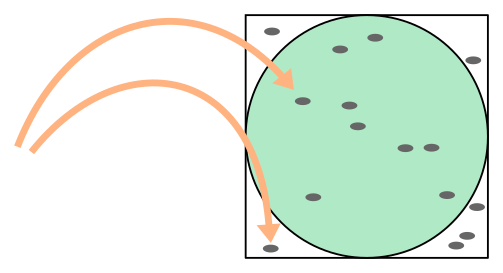
Fig. 1.2 Pebble game: estimating \(\pi/4\) via direct sampling.#
Each pebble landing in the square constitutes a trial and each pebble in the circle a hit. We assume that the children are not too apt at throwing, meaning that most pebbles will actually miss the square (which are collected and thrown again), but when they do land in the square the resulting position is completely random and uniformly so.
By keeping track of the number of trials and hits, the children perform a direct-sampling Monte Carlo computation of \(\pi / 4\), because
The reason this is called direct sampling is because the children have a purely operational way of producing trials independently with the desired distribution (the uniform distribution in the square). Let us write a python program to simulate the outcome of this game with \(4000\) trials.
import numpy as np
# we make a habit of using NumPy's pseudorandom number generator
rng = np.random.default_rng()
def random_in_square():
"""Returns a random position in the square [-1,1)x[-1,1)."""
return rng.uniform(-1,1,2)
def is_in_circle(x):
return np.dot(x,x) < 1
def simulate_number_of_hits(N):
"""Simulates number of hits in case of N trials in the pebble game."""
number_hits = 0
for i in range(N):
position = random_in_square()
if is_in_circle(position):
number_hits += 1
return number_hits
trials = 4000
hits = simulate_number_of_hits(trials)
print(hits , "hits, estimate of pi =", 4 * hits / trials )
3129 hits, estimate of pi = 3.129
This estimate is not too far off, but it is clear that the outcome still has some randomness to it. This is apparent when we look at the result of repeated experiment:
# build an array with the outcome of 10 repetitions
[simulate_number_of_hits(trials) for i in range(10)]
[3169, 3105, 3196, 3191, 3127, 3131, 3174, 3144, 3082, 3146]
Each of these outcomes gives an approximation of \(\pi\) and we will see shortly how to compute the statistical errors expected from this Monte Carlo simulation. For now we interpret the outcomes in terms of the main principle of the direct-sampling Monte Carlo method and many of its variants. Let \(p(\mathbf{x})\mathrm{d}\mathbf{x}\) be a probability distribution on a continuous sample space \(\Omega\) parametrized by \(\mathbf{x}\in\Omega\), meaning that \(p(\mathbf{x})\) is non-negative and \(\int_\Omega p(\mathbf{x})\mathrm{d}\mathbf{x} = 1\). Furthermore we let \(\mathcal{O}(\mathbf{x})\) be an observable or random variable, i.e. a real or complex function on \(\Omega\). Then the expectation value of \(\mathcal{O}\) is given by
Instead, we can look at a sampling \(\mathbf{x}_1, \mathbf{x}_2, \ldots \in \Omega\) of points that are each distributed according to \(p\) and independent of each other. Central to Monte Carlo simulations is that we can approximate \(\mathbb{E}[ \mathcal{O} ]\) via
Of course the approximation gets better with increasing number \(N\) of samples, how fast we will see in next week’s lecture (but you will already perform an empirical study in the Exercise sheet). Note that the probability distribution \(p\) does not occur on the right-hand side anymore, so we have transfered the problem of integrating \(\mathcal{O}\) against the probability distribution \(p(\mathbf{x})\mathrm{d}\mathbf{x}\) to the problem of generating samples \(\mathbf{x}_i\) and evaluating the observable on the samples.
How does our pebble game fit into this mathematical language? Here the sample space \(\Omega\) is the square \(\Omega = (-1,1)^2\) and the probability distribution is the uniform distribution \(p(\mathbf{x}) = 1/4\), which indeed satisfies \(\int_\Omega p(\mathbf{x}) \mathrm{d}\mathbf{x} = \int_{-1}^1 \mathrm{d}x \int_{-1}^1 \mathrm{d}y \,\tfrac14 = 1\). What is the observable \(\mathcal{O}\)? We are interested in the ratio of hits to trials. If we denote the number of trials by \(N\) then we can express this as
where \(\mathcal{O}(\mathbf{x}_i) = 1\) if \(\mathbf{x}_i\) is inside the circle and it is equal to 0 otherwise. In other words \(\mathcal{O}\) is the indicator function \(\mathbf{1}_{\{ x^2 + y^2 < 1 \}}\) on the set \(\{ x^2 + y^2 < 1 \} \subset \Omega\). The expectation value of this observable is
in agreement with the calculation (1.1) above.
1.2. Markov-chain sampling: pebble game 2.0#
The sampling problem in the pebble game is simple enough that we did not have to think twice how to design a direct sampling algorithm. For problems we will encounter later on this will be much more difficult and in many cases finding an efficient such algorithm is unfeasible. A more versatile technique is Markov chain sampling in which samples are not generated independently, as in the direct-sampling method, but via a Markov chain: samples are generated sequentially in a way that only depends on the previous sample (and not the full history of samples).
To introduce the principle we examine a variant of the pebble game to estimate the value of \(\pi\). The goal is the same: the children wish to sample random positions in the square by throwing pebbles. This time however the square with inscribed circle is much larger (let’s say the children moved to the local park), and extends beyond the range of a child’s throw. To simplify matters we assume a single child is playing the game. The procedure of the game is altered as follows. The child starts in some predetermined corner of the square with a bag full of pebbles. With closed eyes she throws the first pebble in a random direction and then she walks to where it has landed, but not touching it. From that position a new pebble is thrown and the procedure repeats. The goal is still to evenly sample from the square in order to estimate \(\pi\). Now a problem arises when a pebble lands outside of the square. In the direct-sampling version, such an event was simply ignored and the pebble was just thrown again. In the new version of the game, however, a choice has to be made what to do with the out-of-range pebble and how to continue in such an event. Let us examine the consequences of different choices numerically.
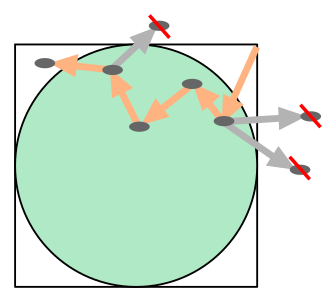
Fig. 1.3 Pebble game: estimating \(\pi/4\) via a Markov chain.#
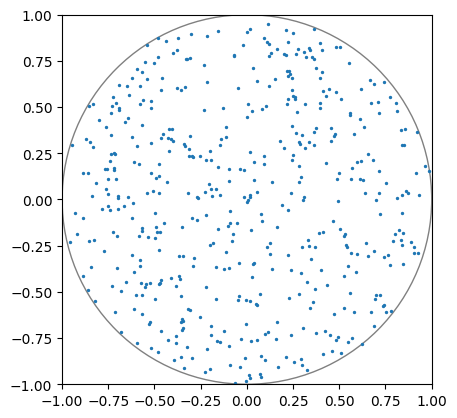
We model the throw of a pebble by a random displacement within a disk of radius \(\delta\). Based on the previous game we already know a way of sampling a uniform random point in a disk, using direct sampling and rejection:
def random_in_disk():
"""Returns a uniform point in the unit disk via rejection."""
position = random_in_square()
while not is_in_circle(position):
position = random_in_square()
return position
# let us test this visually
import matplotlib.pylab as plt
# tell jupyter to display graphics inline
%matplotlib inline
# sample 500 points in NumPy array
testpoints = np.array([random_in_disk() for i in range(500)])
# make a plot
fig, ax = plt.subplots()
ax.set_xlim(-1,1) # set axis limits
ax.set_ylim(-1,1)
ax.set_aspect('equal') # preserve aspect ratio of the circle
ax.add_patch(plt.Circle((0,0),1.0,edgecolor='gray',facecolor='none'))
plt.scatter(testpoints[:,0],testpoints[:,1],s=2)
plt.show()
In our first version of this game the child discards any pebbles that end up outside of the square and stays in place before throwing the next. We can simulate this as follows.
def is_in_square(x):
"""Returns True if x is in the square (-1,1)^2."""
return np.abs(x[0]) < 1 and np.abs(x[1]) < 1
def sample_next_position_naively(position,delta):
"""Keep trying a throw until it ends up in the square."""
while True:
next_position = position + delta*random_in_disk()
if is_in_square(next_position):
return next_position
def naive_markov_pebble(start,delta,N):
"""Simulates the number of hits in the naive Markov-chain version
of the pebble game."""
number_hits = 0
position = start
for i in range(N):
position = sample_next_position_naively(position,delta)
if is_in_circle(position):
number_hits += 1
return number_hits
trials = 40000
delta = 0.3
start = np.array([1,1]) # top-right corner
hits = naive_markov_pebble(start,delta,trials)
print(hits , "hits out of", trials, ", naive estimate of pi =", 4 * hits / trials )
33699 hits out of 40000 , naive estimate of pi = 3.3699
This estimate does not look particularly good, reporting an estimate of \(\pi\) that is above target. Whether the deviation is significant or not, we can only decide after discussing the statistical errors. But comparing to the direct-sampling estimates we should be getting suspicious. This suspicion is confirmed when we look at a histogram of trials in the square:
def naive_markov_pebble_generator(start,delta,N):
"""Same as naive_markov_pebble but only yields the positions."""
position = start
for i in range(N):
position = sample_next_position_naively(position,delta)
yield position
# collect an array of points
trials = 40000
delta = 0.4
start = np.array([1,1])
testpoints = np.array(list(naive_markov_pebble_generator(start,delta,trials)))
# make a plot
fig, ax = plt.subplots()
ax.set_xlim(-1,1)
ax.set_ylim(-1,1)
ax.set_aspect('equal') # preserve aspect ratio of the square
plt.hist2d(testpoints[:,0],testpoints[:,1], bins=10, vmin=0)
plt.colorbar()
plt.show()
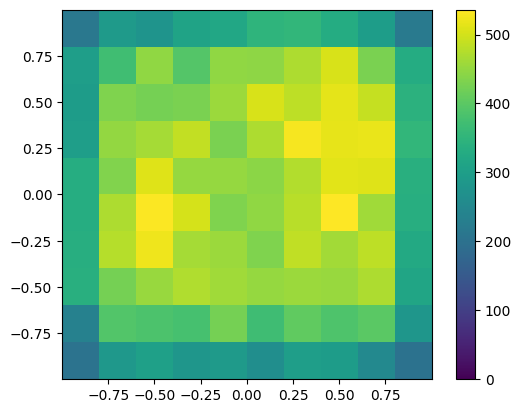
We clearly observe that the density of points near the boundary is lower compared to the central region. This means that the algorithm is not sampling properly from the uniform distribution on the square, but from some more complicated distribution. Can you think of a reason why this is the case?
A different choice in the case of an out-of-range throw is not to discard the pebble, but to have it retrieved and deposited at the location from where it was thrown before continuing to throw the next pebble. We call this a rejection. Note that there was already a pebble at that location from the previous throw, so at every rejection the pile of pebbles at the current location is increased with one. After the desired number of trials (i.e. pebbles deposited in the square), the number of hits within the circle can be counted. Note that the distribution of pebbles will be quite different compared to the direct sampling before: close to the boundary (more precisely, within distance \(\delta\)) many of the pebbles will be part of piles, while in the central region no piles are to be found. Indeed, the chance that pebbles end up at the exact same position there is zero, just like in the direct sampling.
Let us simulate this process.
def sample_next_position(position,delta):
"""Attempt a throw and reject when outside the square."""
next_position = position + delta*random_in_disk()
if is_in_square(next_position):
return next_position # accept!
else:
return position # reject!
def markov_pebble(start,delta,N):
"""Simulates the number of hits in the proper Markov-chain version of the pebble game."""
number_hits = 0
position = start
for i in range(N):
position = sample_next_position(position,delta)
if is_in_circle(position):
number_hits += 1
return number_hits
trials = 40000
delta = 0.3
start = [1,1]
hits = markov_pebble(start,delta,trials)
print(hits , "hits out of", trials, ", estimate of pi =", 4 * hits / trials )
31288 hits out of 40000 , estimate of pi = 3.1288
Judging by this single estimate we are already much closer to the exact value \(\pi = 3.1415\ldots\), and we might be inclined to trust this algorithm. Let us also have a look at the histogram:
def markov_pebble_generator(start,delta,N):
"""Same as markov_pebble but only yields the positions."""
position = start
for i in range(N):
position = sample_next_position(position,delta)
yield position
# collect an array of points
trials = 40000
delta = 0.4
start = np.array([1,1])
testpoints = np.array(list(markov_pebble_generator(start,delta,trials)))
# make a plot
fig, ax = plt.subplots()
ax.set_xlim(-1,1)
ax.set_ylim(-1,1)
ax.set_aspect('equal') # preserve aspect ratio of the square
plt.hist2d(testpoints[:,0],testpoints[:,1], bins=10, vmin=0)
plt.colorbar()
plt.show()
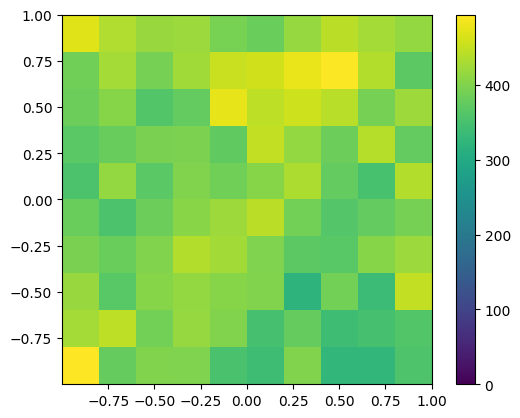
Although the distribution over the square is not exactly uniform we do not observe a clear preference for the boundary versus center region anymore. Indeed we will convince ourselves later that with very many trials the distribution of pebbles approaches the uniform distribution, implying that the ratio of hits to trials approaches \(\pi/4\). Note that the density of piles is identical to the previous algorithm, but apparently having multiple pebbles per pile in the boundary region exactly balances the reduced density of piles!
The method we see in action is a simple example of what is called the Metropolis algorithm for Markov-chain sampling: at each step of the Markov chain a random move is proposed and then accepted or rejected based on the outcome, and in case of a rejection you stay in place and wait. It should be clear that such a method is less efficient than direct sampling, because it can take many steps for the Markov chain to explore the full domain. This is particularly clear if we take the throwing range to \(\delta\) to be very small. In this case it takes many throws even to leave the starting corner of the square. At the other extreme, if we take \(\delta \gg 1\) almost all throws will result in rejections, leading to relatively few piles with many pebbles. Although in both cases we can prove convergence to the correct distribution, the rate of convergence depends on \(\delta\). A good rule of thumb is to choose the parameters in your Metropolis algorithm, in this case \(\delta\), such that the rejection rate is of order \(1/2\), meaning that half of the proposed moves are rejected. You will test this for the pebble game in the Exercise sheet.
1.3. Markov-chain sampling: a discrete pebble game#
To get a feeling for why the Metropolis algorithm with its rejection strategy works, let us simplify the problem even further. Instead of pebbles landing in a continuous set of locations in the unit square, let us make the domain discrete and only allow the pebbles to end up in a row of \(m\) sites. Accordingly we only allow Markov-chain moves to nearest-neighbor sites and rejections. The goal is to choose the move probabilities such that the distribution after many moves approaches the uniform distribution \(p(i) = 1/m\) for \(i = 1,\ldots,m\).
If the player is in position \(i\) we denote the probability of a move to \(j \in \{i-1,i,i+1\}\) by \(P(i \to j)\). It should be clear that the number of times it jumps \(i \to i+1\) is the same as \(i+1 \to i\) (ok, they can differ by \(1\)). So after many moves these two events will happen with equal probability. For \(i\to i-1\) to occur the player has to be in position \(i\), which happens with probability \(p(i)\), and select the move \(i\to i+1\), with probability \(P( i \to i+1)\). We thus obtain an equation relating the equilibrium distribution \(p\) to the move probabilities,
For this to be satisfied for the uniform distribution \(p(i) = 1/m\), we must have \(P(i \to i+1) = P(i+1 \to i)\). In particular this implies we cannot choose \(P( 1 \to 2) = 1\), because then also \(P( 2 \to 1 ) = 1\) and the player would just oscillate back and forth between the first two sites. Although (1.2) does not have a unique solution, a simple solution clearly is to take all \(P(i \to i\pm 1) = \tfrac12\). Since a player at site \(1\) cannot move to \(0\), we must therefore allow for a rejection, i.e. \(P(1 \to 1) = \tfrac12\), and similarly for site \(m\). Let us verify the validity of this analysis with a simulation.
def simulate_discrete_pebble(m,N):
"""Simulate discrete pebble game of N moves on m sites,
returning a histogram of pebbles per site."""
histogram = np.zeros(m, dtype=int)
position = 0
for i in range(N):
position += np.random.choice([-1,1])
position = max(position, 0)
position = min(position, m-1)
histogram[position] += 1
return histogram
histogram = simulate_discrete_pebble(6,100000)
print(histogram)
plt.bar(range(6),histogram)
plt.show()
[17084 16872 16897 16580 16227 16340]
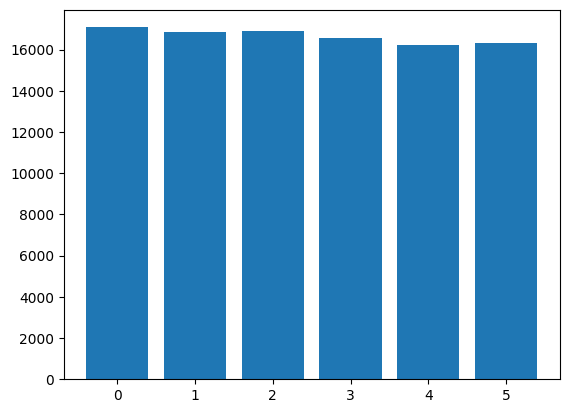
Equation (1.2) is called detailed balance. In this simple example it is a necessary condition to reach the equilibrium distribution \(p\). In general Markov chains this is not the case, but we will see (in the Section Markov Chain Monte Carlo) that imposing detailed balance is a convenient way to design simulations that have the desired equilibrium condition.
1.4. Further reading#
For further reading on this week’s material, have a look at Section 1.1 of [Kra06].
For a first-hand historical account of the birth of the Monte Carlo method have a look at the fascinating autobiography of Stanislaw Ulam, [Ula91].